Introduction
When working at any software, as a developer, you need to know what is going to be delivered to production, for our application code base we use things like git to track changes, keep a history, review and revert if needed. But when we talk about infrastructure resources in our cloud provider, this task is not easy, sometimes because the provider doesn’t have a good API or the tools doesn’t give us what we need, other times is because it is too much complicated, and we are trying to solve something simple as quick as possible, so we do it manually. After doing this a couple of times our account is a mess, with a lot of resources that we don’t use any more, and we only notice that they exist when our manager complains about the bill.
In AWS the service that can help to solve this kind of issue is Cloudformation. A single interface that can be used to describe the desired state of your resources. But even that sometimes is too complicated, too much verbose, or even limited by been static, making us copying and pasting a lot of sections of the big definition file.
Now that’s why CDK was created, a collection of libraries in different languages that can be used to define your infrastructure as code, combining all the advantages of imperative programming languages with the existing workflows that we already defined for our applications.
Let see in this tutorial an example where you can use the CDK tool to manage your infrastructure using Python for a “Webcrawler” service.
TL;DR
See the final source code in Github.
Architecture
As mentioned before, what we will build in this tutorial is a web crawler application, more specifically for apartment rent prices in Dublin city, Ireland. The application will use different services from the AWS cloud provider. See the full picture of the architecture below.
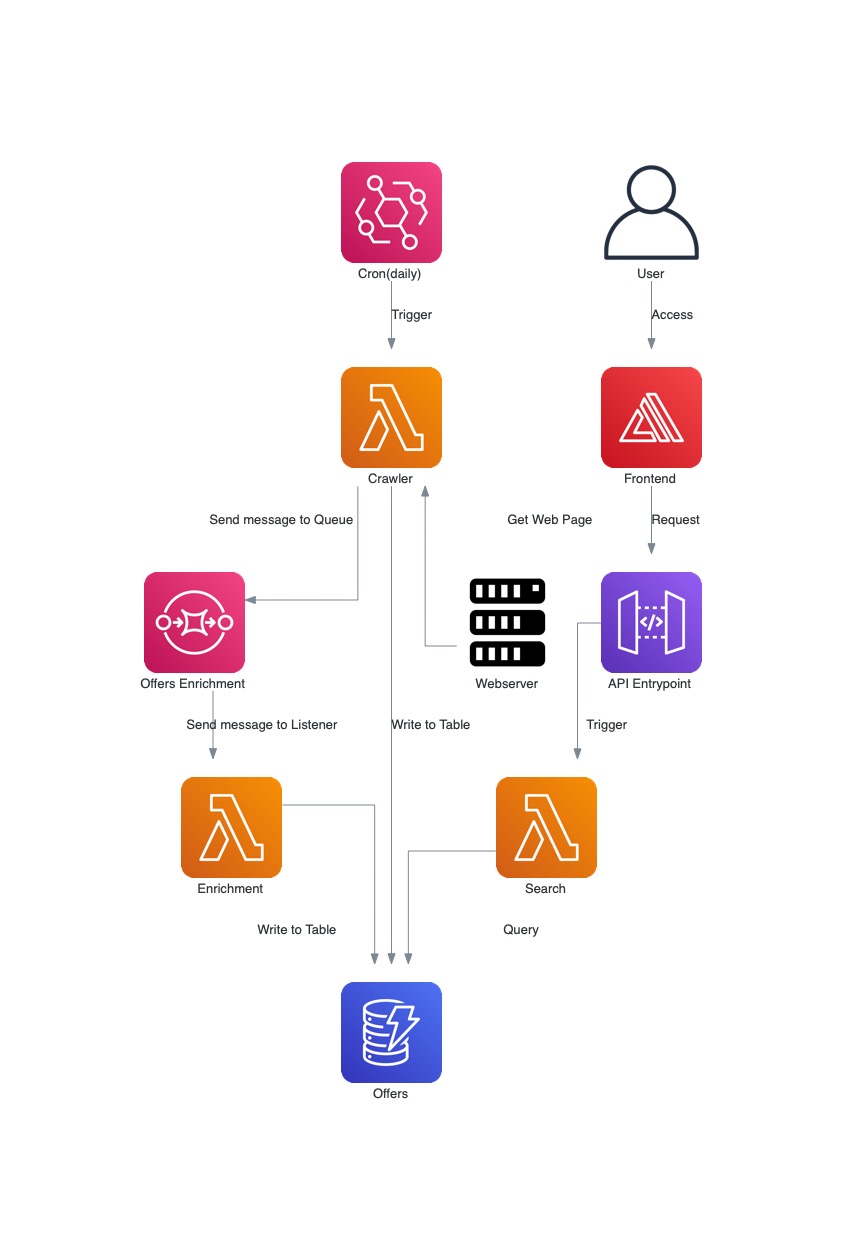
In the example above, the process starts with the Cron, who will be an Eventbridge cron event and will determine the frequency which we collect the page. This event will trigger the Crawler lambda function, that will collect the web page, extract the data, save it to a DynamoDB table and send it at the same time to a SQS queue. The SQS queue will have one listener, our Enrichment lambda, this lambda will be used to add more specialized data to our collected offer, like the distance from the address to the Spire of Dublin in the city centre.
To see the collected data, the user will access a webpage that will be our Frontend, hosted in Amplify. This web page will list all the offers and have some filters, like number of bedrooms and number of bathrooms. This web page also will make requests to our backend, that is an entry point mapped in APIGateway, who by its time will send the request to our Search lambda function. The lambda function will then have the logic to retrieve the data from our DynamoDB table and return to the user.
Getting Started
If you need to install the cdk tool, dependencies and run it for the first time go to my tutorial how to getting started with cdk.
Adding resources
Considering the architecture that we described above, to add all the required resources to the final app_stack.py would be something like below.
import os
from pathlib import Path
from aws_cdk import core as cdk
import aws_cdk.aws_amplify as amplify
import aws_cdk.aws_apigatewayv2 as gateway
import aws_cdk.aws_apigatewayv2_integrations as gateway_integrations
import aws_cdk.aws_codecommit as code
import aws_cdk.aws_ecr as ecr
import aws_cdk.aws_ecr_assets as ecr_assets
import aws_cdk.aws_events as events
import aws_cdk.aws_events_targets as targets
import aws_cdk.aws_lambda as _lambda
import aws_cdk.aws_lambda_event_sources as lambda_event_sources
import aws_cdk.aws_sqs as sqs
import aws_cdk.aws_logs as logs
import aws_cdk.aws_dynamodb as ddb
from database_stack import DatabaseStack
class AppStack(cdk.Stack):
# Utility method to create our lambdas functions with some pre-defined options
def _lambda_function_from_asset(self,
lambda_asset, function_name, function_cmd, environment,
*,
reserved_concurrent_executions=2,
timeout_minutes=15,
memory_size=128,
max_event_age_minutes=60):
return _lambda.DockerImageFunction(self,
function_name,
function_name=function_name,
environment=environment,
# Set log retention to one week to reduce the costs of the CloudWatch service
log_retention=logs.RetentionDays.ONE_WEEK,
# Current tests show that 128MB is sufficient for all lambdas
memory_size=memory_size,
# Limiting the number of concurrent executions will help to reduce the costs of the Lambda service
reserved_concurrent_executions=reserved_concurrent_executions,
timeout=cdk.Duration.minutes(timeout_minutes),
# Enabling tracing to be able to track how much time our lambdas function are taking to finish the execution
tracing=_lambda.Tracing.ACTIVE,
# Limiting to process events only from the last hour, to avoid to process old events
max_event_age=cdk.Duration.minutes(max_event_age_minutes),
# Set a Docker image that would be used to run our lambdas
code=_lambda.DockerImageCode.from_ecr(
lambda_asset.repository,
cmd=[function_cmd],
tag=lambda_asset.image_uri.split(':')[1]))
def __init__(self, scope: cdk.Construct, construct_id: str, db_stack: DatabaseStack, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Enrichment Queue used to receive data from the Crawler and send it to the Enrichment lambda
enrichment_queue = sqs.Queue(self,
"CrawlerEnrichmentQueue",
queue_name='CrawlerEnrichmentQueue',
retention_period=cdk.Duration.days(1),
visibility_timeout=cdk.Duration.minutes(15))
# Default environment variables
env_default = {'APP_LOGGING_LEVEL': 'ERROR'}
# Environment variables used for lambdas that need to know about our DynamoDB table
env_table = {'APP_OFFERS_TABLE': db_stack.offers_table.table_name}
# Environment variables used for lambdas that need to know about our SQS queue
env_queue_url = {'APP_OFFERS_QUEUE_URL': enrichment_queue.queue_url}
# Base Lambda ECR image asset with all the source code of our lambdas functions, see ./src/crawler/Dockerfile
lambda_asset = ecr_assets.DockerImageAsset(self,
'CrawlerLambdaImage',
directory=os.path.join(os.getcwd(), 'src', 'crawler'),
repository_name='crawler')
# Crawler Lambda definition
lambda_crawler = self._lambda_function_from_asset(
lambda_asset,
'LambdaCrawler',
'lambda_handler.crawler',
{**env_default, **env_table, **env_queue_url})
# Set Cron trigger rate of once per hour
rule = events.Rule(self,
'CrawlerCallingRule',
rule_name='CrawlerCallingRule',
schedule=events.Schedule.rate(cdk.Duration.hours(1)))
rule.add_target(targets.LambdaFunction(lambda_crawler))
# Add required permissions
db_stack.offers_table.grant_write_data(lambda_crawler)
enrichment_queue.grant_send_messages(lambda_crawler)
# Enrichment Lambda definition
lambda_enrichment = self._lambda_function_from_asset(
lambda_asset,
'LambdaEnrichment',
'lambda_handler.enrichment',
{**env_default, **env_table})
lambda_enrichment.add_event_source(
lambda_event_sources.SqsEventSource(enrichment_queue))
db_stack.offers_table.grant_write_data(lambda_enrichment)
# Search Lambda definition
lambda_search = self._lambda_function_from_asset(
lambda_asset,
'LambdaSearch',
'lambda_handler.search',
{**env_default, **env_table},
# Allow up to 10 requests per time, throtling users to reduce the lambda service costs
reserved_concurrent_executions=10,
# Give up after 1 minute to avoid to make the user waiting
timeout_minutes=1,
# Explicitly use 128MB of ram
memory_size=128,
# This in combinations with the reserved concurrent executions will help to avoid processing old requests
max_event_age_minutes=1)
db_stack.offers_table.grant_read_data(lambda_search)
# You probably want to change this to your own personal token
personal_token = open(os.path.join(str(Path.home()), '.github/personal_token.txt'), 'r').read()
# Frontend entrypoint definition
amplify_app = amplify.App(self,
'CrawlerFrontend',
app_name='CrawlerFrontend',
auto_branch_creation=amplify.AutoBranchCreation(
auto_build=True),
source_code_provider=amplify.GitHubSourceCodeProvider(
owner='jaswdr',
repository='aws-cdk-crawler-frontend-example',
oauth_token=cdk.SecretValue(personal_token)))
# Backend entrypoint definition
search_entrypoint = gateway.HttpApi(self,
'CrawlerSearchApiEntrypoint',
api_name='CrawlerSearchApiEntrypoint',
cors_preflight=gateway.CorsPreflightOptions(
allow_headers=['*'],
allow_methods=[gateway.HttpMethod.GET],
allow_origins=['*'],
max_age=cdk.Duration.hours(2)),
description='Crawler Search API Entrypoint')
# Adding GET /search route to our backend and pointing it to the Search lambda
search_entrypoint.add_routes(
path='/search',
methods=[gateway.HttpMethod.GET],
integration=gateway_integrations.LambdaProxyIntegration(
handler=lambda_search,
payload_format_version=gateway.PayloadFormatVersion.VERSION_2_0))
As you can see in the example above, I’m declaring all the resources from our previous architecture. For the lambdas I’m using a helper method to standardize the definition, I’m also adding only the environment variables and permissions that each individual lambda need.
Something important to notice, is that there are a lot of recommendations when using cdk, one of those is that you separate your database resources from your application, in this example I’ve split everything in two stacks, the AppStack and the DatabaseStack, the last one handles all the data storage layer of our architecture, with this split we are automatically avoiding touching our data when only changing our application code, you can check the code of this stack below.
import os
from aws_cdk import core as cdk
import aws_cdk.aws_s3 as s3
import aws_cdk.aws_dynamodb as ddb
class DatabaseStack(cdk.Stack):
# Utility helper method to create our DynamoDB table
def _create_ddb_table(self, table_name):
return ddb.Table(self,
table_name,
table_name=table_name,
partition_key=ddb.Attribute(
name="PK",
type=ddb.AttributeType.STRING),
sort_key=ddb.Attribute(
name="SK",
type=ddb.AttributeType.STRING),
# Use on-demand capacity
billing_mode=ddb.BillingMode.PAY_PER_REQUEST,
# Avoid deleting the table even if we delete the stack
removal_policy=cdk.RemovalPolicy.RETAIN,
# Use a time to live field to automatically delete old registers
time_to_live_attribute="TTL")
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
self.offers_table = self._create_ddb_table('Offers')
Now that we have multiple stacks, we need to specify which stack we want to synthesize and deploy.
$ cdk synth DatabaseStack
$ cdk deploy DatabaseStack
$ cdk synth CrawlerAppStack
$ cdk deploy CrawlerAppStack
After finishing both the executions you can access your AWS account and see that everything was created.
Final result

| Layer | Link |
|---|---|
| Backend + Infrastructure | https://github.com/jaswdr/aws-cdk-crawler-backend-example |
| Frontend | https://github.com/jaswdr/aws-cdk-crawler-frontend-example |
Conclusion
Something that all developers do is versioning your code, for obvious reasons like keeping track of changes, review, revert if needed, and to see what will be deployed to production, this is not something trivial when we talk about infrastructure. CDK can be used by writing all your components, their connections and permissions, everything in one place, where you can change it and review it, reverting bad changes, and if we start to talk about the benefits of the cloud, we are finally able to replicate your entirely application stack in different regions for fast recovery. This and more are some benefits of using this tool.