Before we start
If you check for alternatives that we have available for SQL and NoSQL database, both of them have some problems. For SQL databases the problem is scalability, you can of course use them for a lot of applications, they will give you flexibility when you want to retrieve your records, but when you grow, starting to have hundreds of terabytes of data, you will start to see problems related to performance, and that will happen with all SQL database because all of them were created for storage optimization and not compute optimization. Something that was “OK” some years ago when the most expensive part of a datacenter was the storage, but today this sentence is not true anymore.
In the other hand we have NoSQL databases, where we have purpose built database for some common problems. Each NoSQL alternative has its own way to manage data, but all of them have limitations in the way you retrieve data, and thats normally is a consequence by the way the database was built, or the purpose for what it was built. But what all of them have in common is that NoSQL database were built for compute optimization and not storage optimization, this means that when using a NoSQL database you need to be more tolerant about duplication of data, sometimes you need to duplicate your records in favour of performance.
❗ Don’t think that NoSQL databases will replace SQL ones, both have different purposes and each one have its own use case.
So why use Amazon S3 as a NoSQL database? To answer this question we need to think about the advantages and disadvantages of S3.
Advantages of S3
- Serverless
- High availability
- No-management
- “Infinity” scaling
- No-updates
- 99.999999999% of durability (11 9’s)
- Objects size up to 5TB
- Integrated with other AWS services (Lambda, CloudWatch, etc)
- Simple to use
- Secure
Disadvantages of S3
- Limited ways to retrieve data
- Expensive if you don’t know what you are doing
- Eventual consistency
- No-transactions
As we can see, even S3 is not the silver bullet for storage, it has limitations, some of those limitations can make it unfeasible to use in your project, and that is perfectly fine, you know your project and you know what works and what not. But the fact is that for a lot of project it can work, especially with projects where the biggest problem are managing the database, proper scaling, keeping it updated to avoid security breaches and many others. Of course you project should also be tolerant to eventual consistency, not requiring transactions or complex queries, if that applies to your project, you can probably use S3 as a database, so lets see how we can do the most common operations.
Glossary
If you know what Amazon S3 is, skip this section
Amazon S3 has a bunch of terms that are used to define different things, like Buckets who are logical spaces that can have zero or more Objects, those could be anything from text to binary. Each object needs to have a Key, something that is unique within the bucket, in other words we can never have two or more objects with the same key and it’s with the key that we retrieve one or more objects.
Comparing S3 Operations with SQL and NoSQL equivalents
The Amazon S3 has a lot of available operations that we can use, we of course can insert, update and delete records as any database, but when we consider the retrieve of the data is where there is more limitations. Currently S3 only support retrieve objects by key, even when we list all objects we only get the keys and never the content of the object, let’s see how we can work with each operation in S3.
Installing Dependencies
First of all we need to install our dependencies, in this tutorial we will use the Python language and the boto3 library, to install it we can use pip.
$ pip3 install boto3
To test the installation you can execute the follow command.
$ python3 -c "import boto3; print('OK')"
OK
Creating a S3 Client
To start making calls we need a S3 client, we can create one using the boto3.client method.
from pprint import pprint # used for better printing values
import boto3
client = boto3.client('s3')
This client will be the one used in all examples below.
❗ I’m considering that you already have installed the aws CLI tool and configured your account credentials in your aws/config file. If not check this page to see how you can do it.
Creating a Bucket
Every call related to object needs to be related to a bucket, a bucket could be considered our database or depending of the way you model, a bucket can be our table, to create a new one we can use the create_bucket method.
bucket_name = 'jaswdr-tutorial-s3'
response = client.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={'LocationConstraint': 'eu-west-1'})
pprint(response)
{'Location': 'http://jaswdr-tutorial-s3.s3.amazonaws.com/',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '0',
'date': 'Sun, 21 Feb 2021 21:10:42 GMT',
'location': 'http://jaswdr-tutorial-s3.s3.amazonaws.com/',
'server': 'AmazonS3',
'x-amz-id-2': 'BzorIpOFL4xUK1fYD4y2qtrtRTn/l+by35GX6LSw2Hj6IA2OmXv4HeIQ51NM5kDFZKjIwf9ZIt8=',
'x-amz-request-id': '137F63660DCEC22D'},
'HTTPStatusCode': 200,
'HostId': 'BzorIpOFL4xUK1fYD4y2qtrtRTn/l+by35GX6LSw2Hj6IA2OmXv4HeIQ51NM5kDFZKjIwf9ZIt8=',
'RequestId': '137F63660DCEC22D',
'RetryAttempts': 0}}
The important part of the response is first the Location who will be the HTTP endpoint of our bucket and the HTTPStatusCode who needs to be 200 confirming that the bucket was created successfully
Creating or Updating Objects
One of the fundamental operations that we need to do in any database is insert or update our records, to do that with objects in a bucket we can use the put_object method, keep in mind that if the Key that you pass exists the content of the object will be replaced, if not it will be created.
import json
new_user = {
"id": 1,
"username": "foo",
"password": "secret"
}
new_user_key = 'user_{}.json'.format(new_user['username'])
new_user_body = json.dumps(new_user)
response = client.put_object(
Bucket=bucket_name,
Key=new_user_key,
Body=new_user_body)
pprint(response)
{'ETag': '"d6c4952c62396e15a1b6cf2a07dc9fa4"',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '0',
'date': 'Sun, 21 Feb 2021 21:10:43 GMT',
'etag': '"d6c4952c62396e15a1b6cf2a07dc9fa4"',
'server': 'AmazonS3',
'x-amz-id-2': 'XEnCXl3YvbLmYm8GT6RI+JXsc7jv2InNtonok9mH4IUd4vr/akq4V0kqox+34OXM3WaVHnTsX4I=',
'x-amz-request-id': 'D741AF4D35092431'},
'HTTPStatusCode': 200,
'HostId': 'XEnCXl3YvbLmYm8GT6RI+JXsc7jv2InNtonok9mH4IUd4vr/akq4V0kqox+34OXM3WaVHnTsX4I=',
'RequestId': 'D741AF4D35092431',
'RetryAttempts': 0}}
Again the important part is the HTTPStatusCode equals 200 to confirm that the operation was a success. Remember that if the Key already exists the Object is overwritten, that’s how you do updates, if you use an existing key you will lose the previous state of the object unless you have the versioning enabled for your bucket, this is an interesting feature available in S3 that can be used to check the history of a object.
Getting Objects
Once you have added an object, you can retrieve it by the Key using the get_object method.
response = client.get_object(
Bucket=bucket_name,
Key=new_user_key)
user = json.load(response['Body'])
pprint(user)
{'id': 1, 'password': 'secret', 'username': 'foo'}
The response body will contains the content of our user previously created.
Checking Existence of Keys
There are times where you need to check the existence of a key, to do so you can use the head_object method.
response = client.head_object(Bucket=bucket_name, Key=new_user_key)
pprint(response)
{'AcceptRanges': 'bytes',
'ContentLength': 50,
'ContentType': 'binary/octet-stream',
'ETag': '"d6c4952c62396e15a1b6cf2a07dc9fa4"',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Metadata': {},
'ResponseMetadata': {'HTTPHeaders': {'accept-ranges': 'bytes',
'content-length': '50',
'content-type': 'binary/octet-stream',
'date': 'Sun, 21 Feb 2021 21:10:43 GMT',
'etag': '"d6c4952c62396e15a1b6cf2a07dc9fa4"',
'last-modified': 'Sun, 21 Feb 2021 '
'21:10:43 GMT',
'server': 'AmazonS3',
'x-amz-id-2': 'NiNW1wyaC0yAzdt+DjR8L6DUAFyJQtq6LUaYWeUzncRQZu1v1fra26utXEa6sogZIlPW76HXq5Y=',
'x-amz-request-id': '7F350ECC0500E8CF'},
'HTTPStatusCode': 200,
'HostId': 'NiNW1wyaC0yAzdt+DjR8L6DUAFyJQtq6LUaYWeUzncRQZu1v1fra26utXEa6sogZIlPW76HXq5Y=',
'RequestId': '7F350ECC0500E8CF',
'RetryAttempts': 0}}
The HTTPStatusCode been equals 200 confirms that the key exists, we can also see the ContentLength value been greater than 0 to confirm that the object has some content. If the key don’t exist a exception is raised.
response = client.head_object(Bucket=bucket_name, Key='not-existing-key')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.9/site-packages/botocore/client.py", line 357, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/usr/local/lib/python3.9/site-packages/botocore/client.py", line 676, in _make_api_call
raise error_class(parsed_response, operation_name)
botocore.exceptions.ClientError: An error occurred (404) when calling the HeadObject operation: Not Found
Listing Objects
If you need to get a list of keys you can use the list_objects_v2 method.
response = client.list_objects_v2(Bucket=bucket_name)
pprint(response)
{'Contents': [{'ETag': '"d6c4952c62396e15a1b6cf2a07dc9fa4"',
'Key': 'user_foo.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 50,
'StorageClass': 'STANDARD'}],
'EncodingType': 'url',
'IsTruncated': False,
'KeyCount': 1,
'MaxKeys': 1000,
'Name': 'jaswdr-tutorial-s3',
'Prefix': '',
'ResponseMetadata': {'HTTPHeaders': {'content-type': 'application/xml',
'date': 'Sun, 21 Feb 2021 21:10:43 GMT',
'server': 'AmazonS3',
'transfer-encoding': 'chunked',
'x-amz-bucket-region': 'eu-west-1',
'x-amz-id-2': 'cvXe5alJ6ngmDS2v0ihkR8ZYe0VbRZDb8atbglkQeVd0LNqMb+rJvUKIageI0KLrBe/c0zo1wro=',
'x-amz-request-id': '1B8C5977DBBC50D1'},
'HTTPStatusCode': 200,
'HostId': 'cvXe5alJ6ngmDS2v0ihkR8ZYe0VbRZDb8atbglkQeVd0LNqMb+rJvUKIageI0KLrBe/c0zo1wro=',
'RequestId': '1B8C5977DBBC50D1',
'RetryAttempts': 0}}
We can extract some useful information from the response:
- Contents: Contains the returned list of keys, each item in this list contains useful informations like the Key, Size and StorageClass of the Object.
- KeyCount: Contains the number of items returned.
Something that is important to keep in mind when using the list method is that there is a limit in the number of objects returned, by default if you don’t set the parameter MaxKeys it will return 1000 items. Let see how we can use this parameter, but first we need to insert some new items.
for i in range(50):
new_user = {
"id": i,
"username": "foo_{}".format(i),
"password": "secret"
}
new_user_key = 'user_{}.json'.format(new_user['username'])
new_user_body = json.dumps(new_user)
client.put_object(
Bucket=bucket_name,
Key=new_user_key,
Body=new_user_body)
Now that we have some items we can retrieve a specific max number of them when listing Objects.
response1 = client.list_objects_v2(
Bucket=bucket_name,
MaxKeys=3)
pprint(response1)
{'Contents': [{'ETag': '"d6c4952c62396e15a1b6cf2a07dc9fa4"',
'Key': 'user_foo.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 50,
'StorageClass': 'STANDARD'},
{'ETag': '"62fbf6e148994e130cb7fc3a78f8016c"',
'Key': 'user_foo_0.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 52,
'StorageClass': 'STANDARD'},
{'ETag': '"422925d277ce0f901e016bf33e7a9c06"',
'Key': 'user_foo_1.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 52,
'StorageClass': 'STANDARD'}],
'EncodingType': 'url',
'IsTruncated': True,
'KeyCount': 3,
'MaxKeys': 3,
'Name': 'jaswdr-tutorial-s3',
'NextContinuationToken': '1TezI83EEpAMKAolDx5bsAzmykvkMjiRV1EdH8yj0s/Q0mTzLLfnHQyHttB7pBuFo',
'Prefix': '',
'ResponseMetadata': {'HTTPHeaders': {'content-type': 'application/xml',
'date': 'Sun, 21 Feb 2021 21:10:45 GMT',
'server': 'AmazonS3',
'transfer-encoding': 'chunked',
'x-amz-bucket-region': 'eu-west-1',
'x-amz-id-2': 'YTECk2v6WSLf01/StGfZLjgHcJfiPu5Gs2DRkMtq3gV0JJBAbTBBCS+HNzYSW7nQ9AHFbk+vnos=',
'x-amz-request-id': '2EFA458AA3954C96'},
'HTTPStatusCode': 200,
'HostId': 'YTECk2v6WSLf01/StGfZLjgHcJfiPu5Gs2DRkMtq3gV0JJBAbTBBCS+HNzYSW7nQ9AHFbk+vnos=',
'RequestId': '2EFA458AA3954C96',
'RetryAttempts': 0}}
As we can see the response has just 3 items, to retrieve the next 3 items we need to use the NextContinuationToken token value in a new call.
response2 = client.list_objects_v2(
Bucket=bucket_name,
MaxKeys=3,
ContinuationToken=response1['NextContinuationToken'])
pprint(response2)
{'Contents': [{'ETag': '"0a8cb3ea06c2de8aa09118ee96261df5"',
'Key': 'user_foo_10.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 54,
'StorageClass': 'STANDARD'},
{'ETag': '"f61be415447685feee6cec6604a26d9f"',
'Key': 'user_foo_11.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 54,
'StorageClass': 'STANDARD'},
{'ETag': '"467c05af30b59cfe30662f6f1411e6b7"',
'Key': 'user_foo_12.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 43, tzinfo=tzutc()),
'Size': 54,
'StorageClass': 'STANDARD'}],
'ContinuationToken': '1TezI83EEpAMKAolDx5bsAzmykvkMjiRV1EdH8yj0s/Q0mTzLLfnHQyHttB7pBuFo',
'EncodingType': 'url',
'IsTruncated': True,
'KeyCount': 3,
'MaxKeys': 3,
'Name': 'jaswdr-tutorial-s3',
'NextContinuationToken': '1OxuhgN58BR6wcCbNsLyW1yLHwiOE5M2Y0m0is1d6uEzVnnLhNXM0mYDuJ4dSq2qj',
'Prefix': '',
'ResponseMetadata': {'HTTPHeaders': {'content-type': 'application/xml',
'date': 'Sun, 21 Feb 2021 21:10:45 GMT',
'server': 'AmazonS3',
'transfer-encoding': 'chunked',
'x-amz-bucket-region': 'eu-west-1',
'x-amz-id-2': 'gMPdFJhPjoJDZgNfAtoBML33FlzpUp03J3Qs6jtkDESDeOmF+AWiXPEKI7p5lrDw7SFLTkEH0V8=',
'x-amz-request-id': 'EF68EAFEACD58359'},
'HTTPStatusCode': 200,
'HostId': 'gMPdFJhPjoJDZgNfAtoBML33FlzpUp03J3Qs6jtkDESDeOmF+AWiXPEKI7p5lrDw7SFLTkEH0V8=',
'RequestId': 'EF68EAFEACD58359',
'RetryAttempts': 0}}
We can see that the items in the response changed, if we keep using the NextContinuationToken of each response in the next request it will be possible to list all the Objects in our bucket.
Deleting Objects
For deletion we can use the delete_object method.
response = client.delete_object(
Bucket=bucket_name,
Key='user_foo.json')
pprint(response)
{'ResponseMetadata': {'HTTPHeaders': {'date': 'Sun, 21 Feb 2021 21:10:45 GMT',
'server': 'AmazonS3',
'x-amz-id-2': 'JaObHepZthp4FWGQip1RtGpVhFljg5Z53R9qBvcnp29L2R24cYwTHSkpVgwhtzxjRYvJ1DQRRz8=',
'x-amz-request-id': 'EB43577F06FE2C49'},
'HTTPStatusCode': 204,
'HostId': 'JaObHepZthp4FWGQip1RtGpVhFljg5Z53R9qBvcnp29L2R24cYwTHSkpVgwhtzxjRYvJ1DQRRz8=',
'RequestId': 'EB43577F06FE2C49',
'RetryAttempts': 0}}
Something important to notice is that the deletion of objects will succeed even if the object key don’t exist, this is probably a consequence of the “eventual consistency” of S3.
Using Simple Queries
Going to one of the most interesting part, a common operation when using any database is the ability to query to retrieve items that meet a criteria. In SQL databases you use the SELECT statement for that, in NoSQL database we have different ways to do it.
In S3 we don’t have much flexibility for retrieving objects, we can use the list methods to retrieve objects keys, the key can be something like the id of the object. But when we want to filter objects by some attribute we have basically two options, first is to add the attribute in the key of the object, so we can use the Prefix parameter in the list_objects_v2 method, like the example below, where we are creating a role attribute for our user object.
import random
for i in range(10):
new_user = {
"id": i,
"username": "foo_{}".format(i),
"role": "user" if random.randint(0,1) == 0 else "admin",
"password": "secret"
}
new_user_key = 'user_{}_{}.json'.format(new_user['role'], new_user['username'])
new_user_body = json.dumps(new_user)
client.put_object(
Bucket=bucket_name,
Key=new_user_key,
Body=new_user_body)
Listing all users with “user” role.
response = client.list_objects_v2(
Bucket=bucket_name,
Prefix='user_user',
MaxKeys=3)
pprint(response)
{'Contents': [{'ETag': '"62a9301ddbdfa1c20ace0182d8a6f812"',
'Key': 'user_user_foo_0.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 45, tzinfo=tzutc()),
'Size': 68,
'StorageClass': 'STANDARD'},
{'ETag': '"52b2b46093a6c1357765a76f3eef75ce"',
'Key': 'user_user_foo_5.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 45, tzinfo=tzutc()),
'Size': 68,
'StorageClass': 'STANDARD'},
{'ETag': '"87d0cb16803a6a2c8cc9385a5481ccca"',
'Key': 'user_user_foo_8.json',
'LastModified': datetime.datetime(2021, 2, 21, 21, 10, 46, tzinfo=tzutc()),
'Size': 68,
'StorageClass': 'STANDARD'}],
'EncodingType': 'url',
'IsTruncated': False,
'KeyCount': 3,
'MaxKeys': 3,
'Name': 'jaswdr-tutorial-s3',
'Prefix': 'user_user',
'ResponseMetadata': {'HTTPHeaders': {'content-type': 'application/xml',
'date': 'Sun, 21 Feb 2021 21:10:46 GMT',
'server': 'AmazonS3',
'transfer-encoding': 'chunked',
'x-amz-bucket-region': 'eu-west-1',
'x-amz-id-2': 'eaPlf3Dq4aE/CqQdbdE0o4Q+hvE9wjJp+Q3BCWMfqDwy+Rs9LU51UYxGTpmNuD3ycd+oNaL8L/4=',
'x-amz-request-id': 'A184913E7A137123'},
'HTTPStatusCode': 200,
'HostId': 'eaPlf3Dq4aE/CqQdbdE0o4Q+hvE9wjJp+Q3BCWMfqDwy+Rs9LU51UYxGTpmNuD3ycd+oNaL8L/4=',
'RequestId': 'A184913E7A137123',
'RetryAttempts': 0}}
Listing all admin users can done in a similar way, this technique is basically how you create a “index”, of course you can use this with multiple attributes, but because you can only use a prefix when listing you need to respect the order, if you use A, B and C attributes and you want to query for C you need to pass A and B too, and there is no wildcard value that you can use or even regex.
The second way to query objects by attributes is using the select_object_content, but it is only possible to use it to query or filter values from the content of only one object, this method accept multiple formats for input and output, let’s see how it works, but first let create a list of users.
users = ""
for i in range(10):
new_user = {
"id": i,
"username": "foo_{}".format(i),
"role": "user" if random.randint(0,1) == 0 else "admin",
"password": "secret"
}
users += json.dumps(new_user)+"\n"
users_key = "users.json"
client.put_object(
Bucket=bucket_name,
Key='users.json',
Body=users)
{'ResponseMetadata': {'RequestId': '0089E45C25479B03',
'HostId': 'T+Yj8L3GDMepwDwPOv0zW0A63I0W+bLFLJf3zKRf/C8UKwVHE8QQ2zng4na9u9fIzPRzR472Qyg=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'T+Yj8L3GDMepwDwPOv0zW0A63I0W+bLFLJf3zKRf/C8UKwVHE8QQ2zng4na9u9fIzPRzR472Qyg=',
'x-amz-request-id': '0089E45C25479B03',
'date': 'Sun, 21 Feb 2021 21:10:46 GMT',
'etag': '"d190d44ff783594b52c4d28f9f296596"',
'content-length': '0',
'server': 'AmazonS3'},
'RetryAttempts': 0},
'ETag': '"d190d44ff783594b52c4d28f9f296596"'}
This will generate a list of users in the users.json key, now we can query it.
response = client.select_object_content(
Bucket=bucket_name,
Key=users_key,
ExpressionType="SQL",
Expression="SELECT * FROM S3Object s WHERE s.role = 'admin'",
InputSerialization={"JSON": {"Type": "Document"}},
OutputSerialization={"JSON": {}})
pprint(response)
{'Payload': <botocore.eventstream.EventStream object at 0x10720f580>,
'ResponseMetadata': {'HTTPHeaders': {'date': 'Sun, 21 Feb 2021 21:10:46 GMT',
'server': 'AmazonS3',
'transfer-encoding': 'chunked',
'x-amz-id-2': 'RbjooT13midyPl1BRRB5ll2YZegG3/nkOgo9q84KeKePLn3rZf08wJfGuD99JmY4FBAwTYupTTE=',
'x-amz-request-id': 'DD9DCCECA680CC81'},
'HTTPStatusCode': 200,
'HostId': 'RbjooT13midyPl1BRRB5ll2YZegG3/nkOgo9q84KeKePLn3rZf08wJfGuD99JmY4FBAwTYupTTE=',
'RequestId': 'DD9DCCECA680CC81',
'RetryAttempts': 0}}
Something to notice in the response is that the Payload returns an EventStream, this means we don’t get our full response back immediately, we need to iterate over this object to get our response, and convert the values back to dict.
payload = list(response['Payload'])[0]['Records']['Payload']
records = payload.decode('utf-8').strip().split('\n')
list(map(json.loads, records))
[{'id': 0, 'username': 'foo_0', 'role': 'admin', 'password': 'secret'},
{'id': 3, 'username': 'foo_3', 'role': 'admin', 'password': 'secret'},
{'id': 4, 'username': 'foo_4', 'role': 'admin', 'password': 'secret'},
{'id': 5, 'username': 'foo_5', 'role': 'admin', 'password': 'secret'},
{'id': 6, 'username': 'foo_6', 'role': 'admin', 'password': 'secret'},
{'id': 7, 'username': 'foo_7', 'role': 'admin', 'password': 'secret'},
{'id': 9, 'username': 'foo_9', 'role': 'admin', 'password': 'secret'}]
It works! and you can see that it is a bit tricky to convert them back to dict objects, but the filtering works as expected.
Doing Complex Queries
Know that we saw how to do simple queries you can think that maybe this is not much useful for you project, because you need to do something more complex queries, like the ones you do in SQL databases, but the truth is that you cannot think that way, you need to understand that you can’t use a NoSQL database as a SQL database, those are different use cases, even if you can think this and consider it for small applications, you cannot scale it for too long.
So, to do complex queries using S3 we have a bunch of alternatives, one of this are for example using two other AWS services, AWS Lambda and Amazon SNS. Those two services can be used for complex data analysis by sending S3 events to a SNS topic, events happen when we put, delete or do any object level operation, and process them using Lambda functions, extracting the results we want, below you can see the architecture for this example.
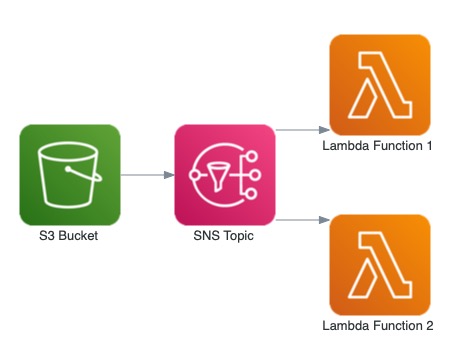
Of course this is one way to do it, some other alternatives are using SQS or even Kinesis for more complex scenarios.
Conclusion
Amazon S3 could be a solution to avoid a bunch of problems that we have when using traditional or even state of the art databases. It gives you a simple API that is easy to understand, but is still limited, to process more complex data, or generate complex aggregations or statistics we need to use different approaches, like using other AWS services that can integrated to provide the data you want, by consequence this brings a lot of flexibility, but it depends on the size of your project and your budget.